

“سقراط معتقد بود که زندگی آزموده نشده، ارزش زیستن ندارد. شاید در دنیای کاری، بتوانیم این جمله سقراط را اینگونه معنا کنیم : پروژهای که نتوان اثراتش را اندازهگیری کرد، ارزش انجام شدن ندارد...”
پشتصحنه تکنیکال سئو در بزرگترین ایکامرس ایران، دیجیکالا
نوشتن اعداد کار سادهایه چه اعداد تک رقمی چه اعداد میلیونی.حتی صحبت در مورد اعداد هم راحته، اما رسیدن به اون اعداد چطور؟ اینجاست که چیزی مهمتر از خود اعداد وجود داره، و اون مسیر طی شده برای رسیدن به اون اعداده.
۲ میلیون صفحه جدید ایندکس شده، افزایش ۳.۷ میلیونی ایمپرشن و ۴۹۳ هزار کلیک بیشتر. این اعداد هم مثل هر عدد دیگری، راحت نوشته شدند، اما رسیدن بهشون راحت نبود…
در این case study، به تفصیل به بررسی چگونگی و اثرات مختلف اپتیمایزیشن سایت مپ دیجیکالا، به عنوان بزرگترین فروشگاه آنلاین ایران، با بیش از ۱۶ میلیون پروداکت منحصر به فرد میپردازیم. اگر شما هم دوست دارید بدونید که این اعداد چطوری بدست اومدند و چه مسیری برای بدست آوردن این اعداد طی شدند، این کیساستادی مهمترین چیزیه که امروز باید بخونید.
سرفصل ها
- صورت مسئله و چالشها
- ایمپکتها و تاثیرات پروژه
- نتایج و مقایسه فازهای انجامشده پروژه
- مسیر پروژه و اقدامات انجامشده
- جمعبندی
همونطور که میدونیم، فایل سایت مپ، نقش مهم و بسزایی در بهبود متریکهایی از قبیل : تعداد صفحات ایندکس شده، کراول باجت، دسترسی پذیری urlها، ایمپرشن و در نهایت بهبود ترافیک ارگانیک یک وبسایت داره.
در پروژه اپتیمایزیشن سایتمپ در سایتهای بزرگ مانند دیجیکالا، به علت تکنولوژی استفاده شده، حجم میلیونی urlهای سایت، تیمهای درگیر مختلف و …، چالشهای گوناگون و بیشتری در مقایسه با سایر سایتها که از cms هایی مانند وردپرس و از طریق پلاگینهای مختلف مدیریت و ساخته میشن به وجود میاد که این چالشها، ما رو به این سمت برد که به دنبال راهحلهای هوشمندانه، قابل کنترل، قابل اندازهگیری و اسکیل پذیر برای بهینهسازی این مورد باشیم.
در این پروژه، چالش اصلی ایندکس نشدن بخش قابل توجهی از صفحات سایت ( مخصوصا صفحات /product ) و استفاده نشدن از پتانسیل بزرگ موجود در سایتمپ، با توجه به اسکیل بزرگ دیجیکالا، اولویت اصلی پروژه بود و به کمک راهحلی که در ادامه به طور کامل توضیح داده شده، تونستیم این چالش رو تا حد قابل توجهی حل کنیم و به نتایج قابل توجهی، مثل آنچه که در بالاتر ذکر شد، یعنی رشد ۳۹ درصدی در ایمپرشن و ۳۶ درصدی در کلیک صفحات پروداکت برسیم.
صورت مسئله و چالشها
قبل از اینکه به بررسی بخشهای مختلف این کیساستادی بپردازیم، لازمه بدونیم که اولا چه شد که ما به فکر ایجاد چنین پروژهای افتادیم و چه مشکلاتی در وهله اول، توجه ما به این مسئله رو جلب کرد.
سایت مپ دیجیکالا، شامل یکسری فایل با فرمت .gz هست که داخل هر کدام از این فایلها، چندین فایل با فرمت .xml وجود داره. در بررسیهای مختلفی که بر روی دایرکتوریهای مختلف سایت مانند صفحات pdp, plp, tag, facet و … داشتیم، متوجه شدیم که الزاما، تمام urlهای سئومحور ( urlهایی که برای سئو اهمیت دارند ) در سایت مپ وجود ندارند.
همچنین در برخی از اوقات، به دلیل نحوه ساخته شدن فایل سایت مپ، تعداد فایلهای .gz موجود در سایت مپ، کم و زیاد میشد. برای مثال در برخی از اوقات، تنها ۱۳ فایل gzip داخل سایت مپ دیده میشد و گاهی حدود ۲۰۰ فایل.
همچنین ارورهای مختلفی در سرچ کنسول سایت هم در این راستا دیده میشد :
اروری که مشخصا گواه بر این بود که از بین میلیونها url موجود در دیجیکالا، تنها حدود ۳ هزار لینک توسط کرالرها دیده شده بودند.

چالش دیگری که مخصوصا در کار در شرکتهای اینترپرایز و بزرگی مثل دیجیکالا خودش رو نشون میده، عدم وجود داکیومنتهای دقیق و مستند، از اینکه چه فعالیتهایی برای پروژههای این چنینی در گذشته انجام شده و همچنین چه کسانی اونر مستقیم این مسئله بودند و با چه کسانی باید برای بهبود تسکهای مختلف صحبت بشه وجود داره که کار رو برای پیگیری، ایجاد نیازمندیهای تکنیکالی و درک دقیق صورت مسئله به شدت سخت و پیچیده میکنه.
“چالش دیگری که مخصوصا در کار در شرکتهای اینترپرایز و بزرگی مثل دیجیکالا خودش رو نشون میده، عدم وجود داکیومنتهای دقیق و مستنده…”
در نهایت چه میشه کرد؟ شاید معمار به گذاشتن خشت اول توجه زیادی نداشته، اما ما میدونیم که همواره هرچیزی رو میشه بهینهتر کرد…
ایمپکتهای این پروژه
بعد از پیادهسازی تغییرات انجام شده، تنها در عرض ۲ ماه، شاهد تغییرات چشمگیر و تاثیرات بزرگی در نرخ کراول صفحات پروداکت، دسترسی پذیری تصاویر محصولات، تعداد صفحات ایندکس شده ( صفحات پروداکت )، و متریکهای اصلی یعنی کلیک و ایمپرشن این صفحات بودیم.
برای حفظ محرمانگی اطلاعات، طبیعتا از گذاشتن برخی از دیتاهای دقیق سرچ کنسول معذورم. اما به طور کلی، در جدول زیر، میتونید تمامی تغییرات مثبتی که در این بهینهسازی بر روی متریکهای مختلف انجام شد رو مشاهده کنید. در ستون اول، سکشن بررسی شده در سرچ کنسول، ستون دوم متریک مدنظر و در ستون سوم، میزان رشد هر کدام از متریک ها رو میبینید.
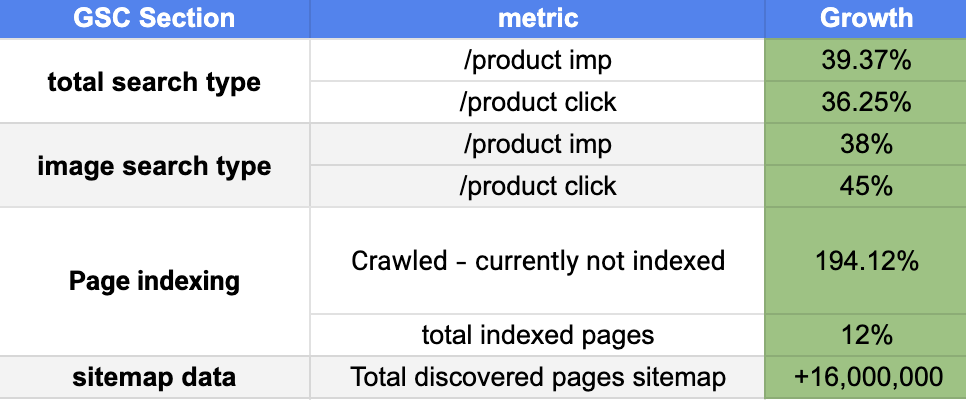
Total search type : رشد ۳۹ درصدی در ایمپرشن، و ۳۶ درصدی در کلیک صفحات پروداکت، جذابترین و عینیترین ایمپکت این پروژه بود. دیتایی که به تنهایی، نشوندهنده تاثیر انجام بیگ پراژکتهای این چنینی،بر روی متریکهای مستقیم و مرتبط با سئوست.
Image search type : بخش جستجوی تصاویر گوگل، یکی از مواردیه که همواره مورد غفلت قرار می گیره، اما میدونیم که با ظهور ai و تغییر نحوه جستجو کاربران، نمیتونیم از این بخش به سادگی عبور کنیم. استفاده از گوگل لنز، جستجوی معکوس تصاویر و سایر ابزارهای جستجوگر تصاویر، نشون دهنده اهمیت بهینهسازی در این بخشه. رشد ۳۸ درصدی و همچنین ۴۵ درصد کلیک بیشتر، یکی دیگه از ایمپکتهای مهم این پروژه بود.
Page Indexing : متریکهای مرتبط با ایندکس صفحات هم، یک متریک مهم دیگه در ارزیابی فعالیتهای انجام شده ما بود. طبیعتا تا زمانی که صفحات ما ایندکس نباشند، صحبت در مورد کلیک و ایمپرشن بیهودست. رشد ۱۹۴ درصدی در صفحاتی که کرالرهای گوگل به تازگی کراولشون کردند و همچنین رشد ۱۲ درصدی در ایندکس صفحات پروداکت، نشوندهنده تاثیر مستقیم کارهای انجام شده در بهینهسازی سایت مپ بود.
Sitemap data : در نهایت، خروجیای که به دنبالش بودیم رو در این بخش میبینیم. سوالی که ما رو به دنبال بررسی و بهینهسازی این بخش برد – ( آیا همه پروداکتهای ما در سایت مپ هستند یا خیر؟ ) – و در نهایت خیالمون رو راحت کرد که با اطمینان، بتونیم به این سوال، پاسخ “بله” بدیم.
نتایج و مقایسه فازهای انجامشده
یک نکته خیلی مهم که همواره در انجام چنین پروژههایی باید بررسی شوند ، استفاده از رویکرد before & after برای مشاهده تغییرات انجام شده است.
از قدیم گفتند که اگر شما توانایی اندازهگیری چیزی رو نداشته باشید، پس عملا نمیتونید بهترش کنید.
“If you can’t measure something, you can’t improve it.”
به خاطر همین، زمانی که فاز اول پروژه رو در بازه زمانی قبلی این پروژه انجام شد، خروجی دیتا برای مقایسه در آینده ذخیره شد. در ادامه به بررسی تغییرات انجام شده در مقایسه با دیتای اولیه می پردازیم. دیتاهایی که خیلی جالبند و اثر اولیه این پروژه بر سوال و دغدغه اصلی ما یعنی وجود یا عدم وجود پروداکتهای ما در سایت مپ رو نشون میدن.

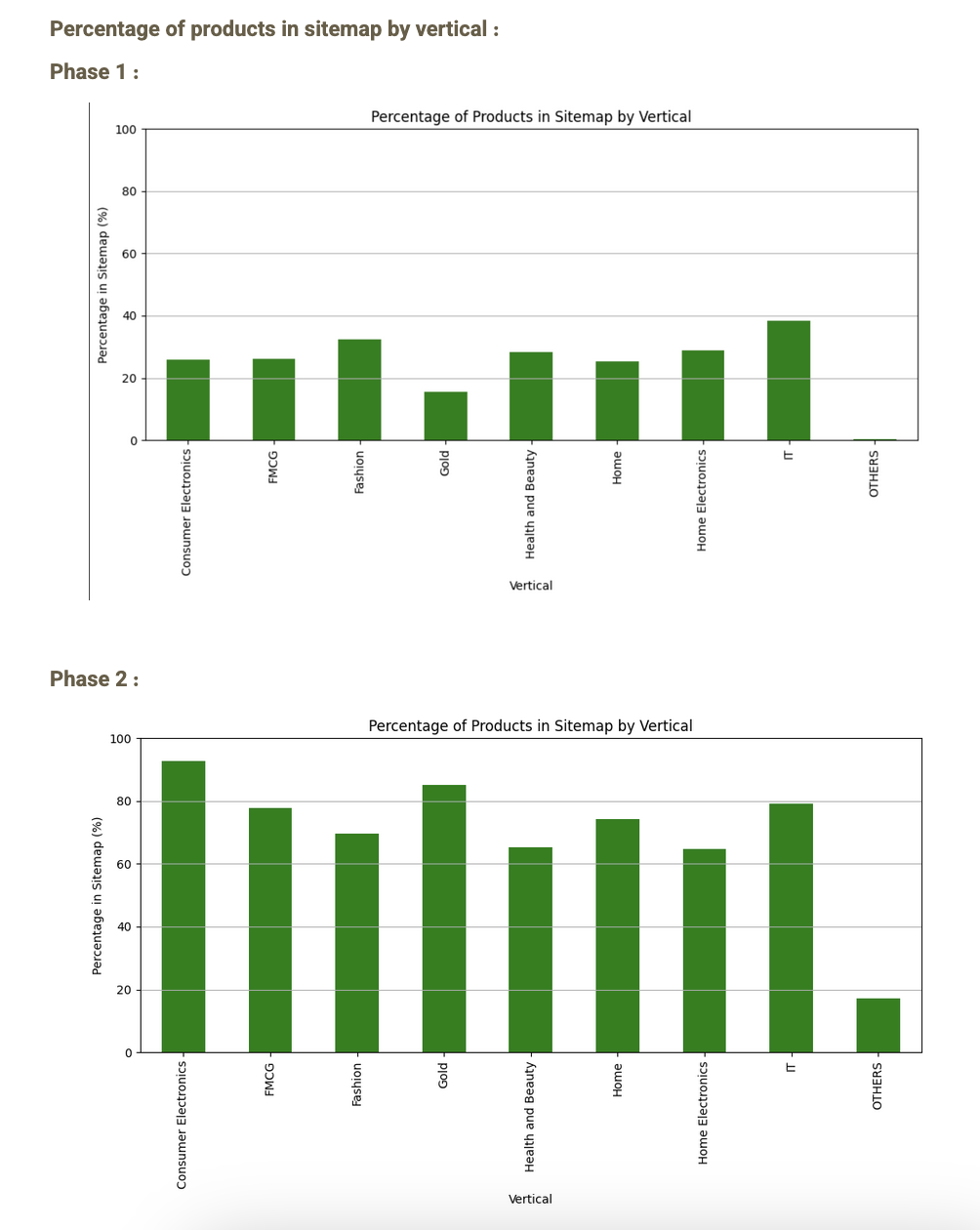
در فاز اول، تنها ۵ میلیون پروداکت در سایت مپ داشتیم که در فاز دوم، با ایجاد تغییرات انجام شده، این مورد به ۱۵ میلیون رسید.

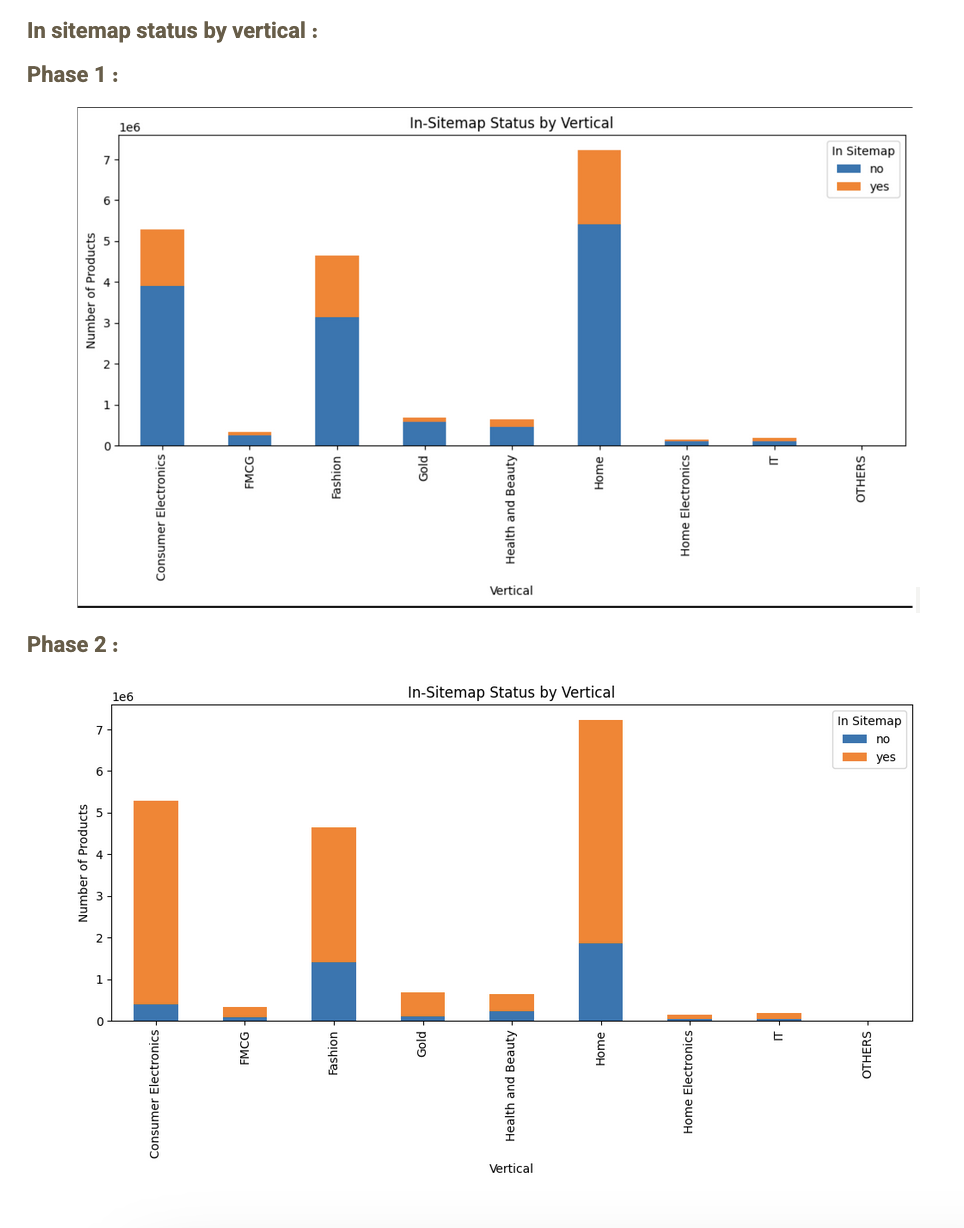
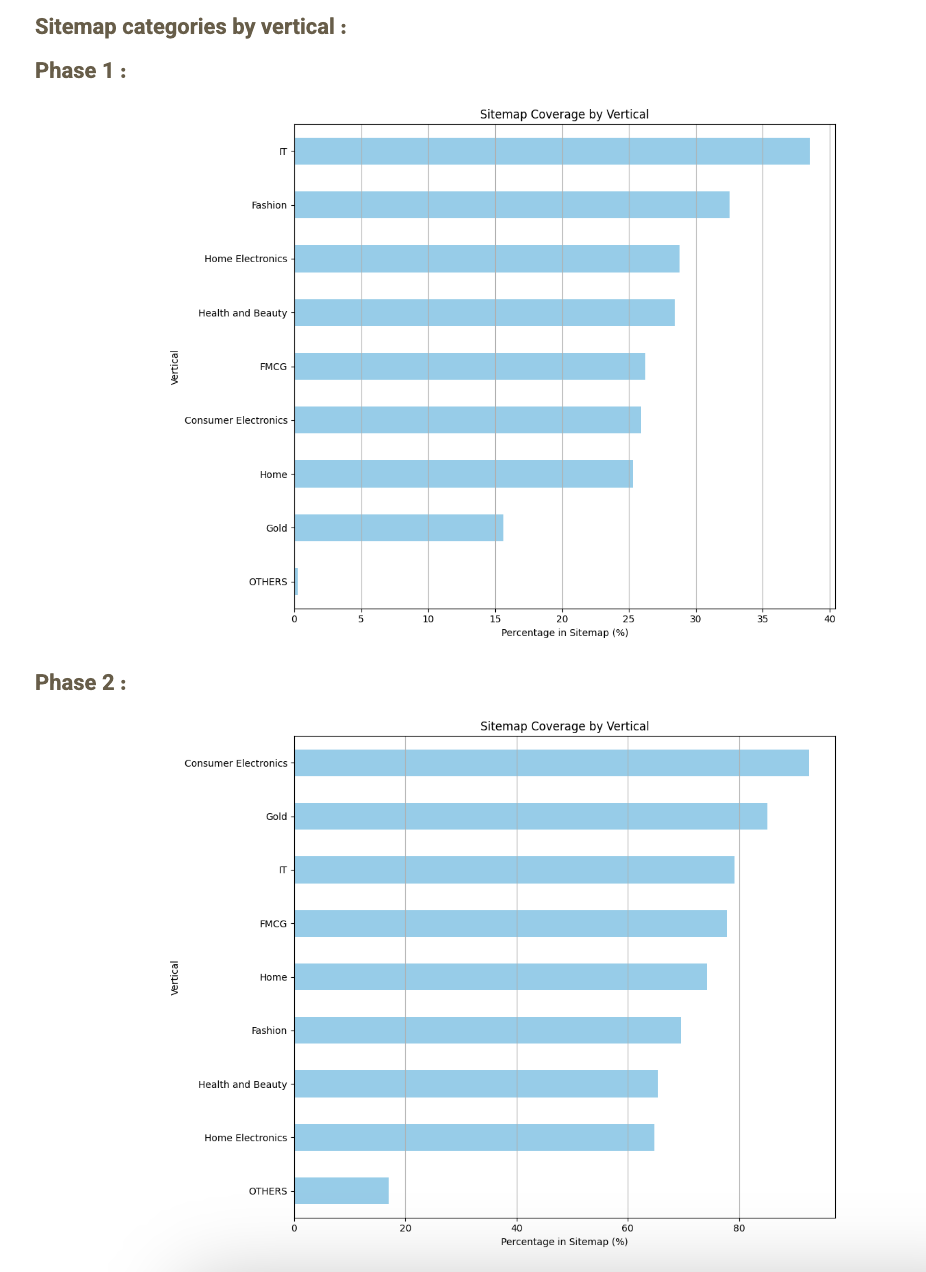
در تصویر زیر، نرخ وجود یا عدم وجود پروداکت بر اساس ورتیکالهای مختلف رو میبینید که در دو فاز اول و دوم باهمدیگه مقایسه شدهاند :
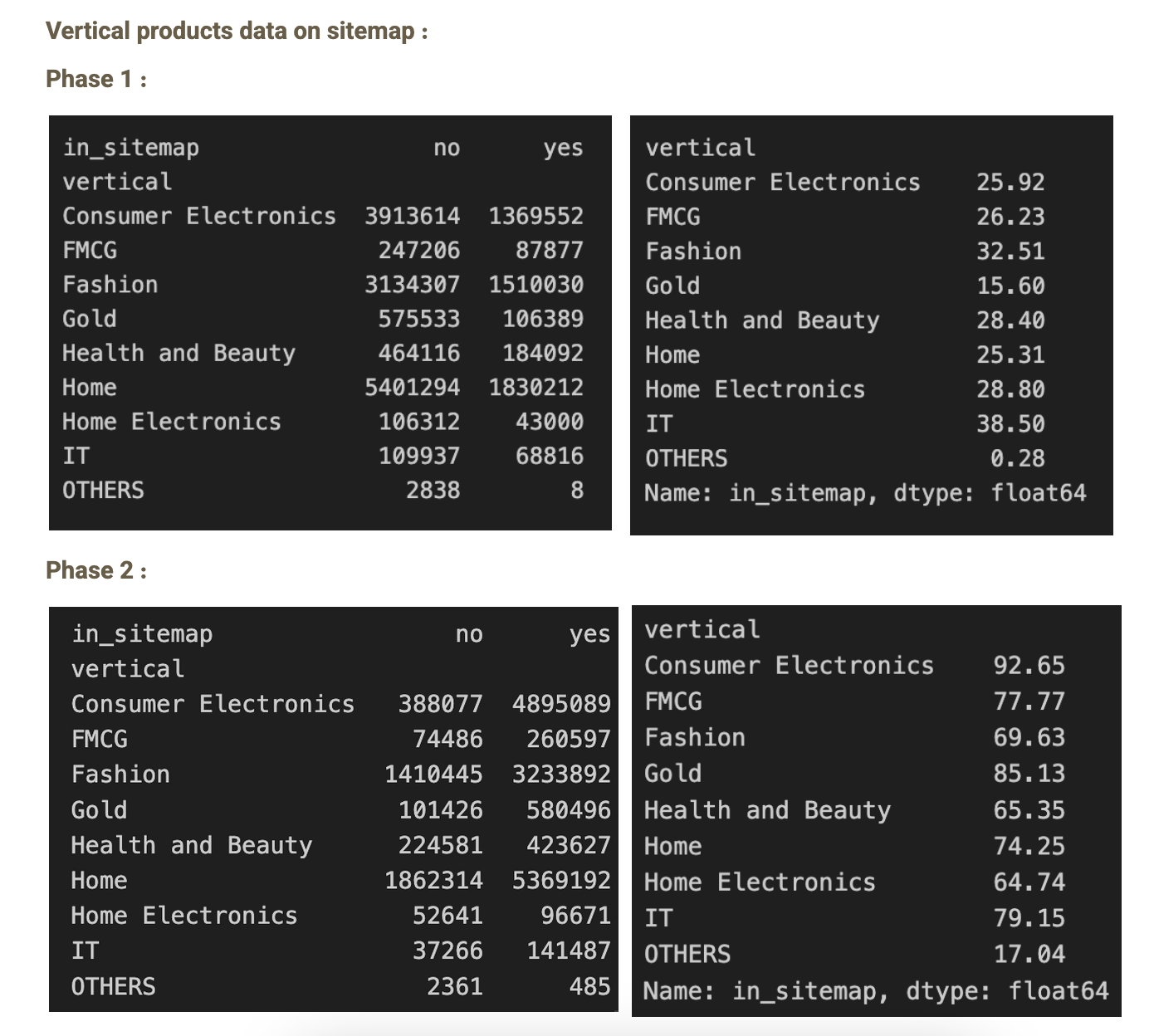
همونطور که میبینید، اگر این مسئله رو به صورت ورتیکالی بسنجیم، متوجه میشیم که میانگین درصد وجود پروداکتهای هر ورتیکال از ۲۷ درصد در فاز اول و قبل از انجام تغییرات و فیکس سایت مپ، به نرخ 75 درصد میرسه. ( البته نکته اینه که خیلی از پروداکتهایی که ما به صورت لوکال خروجی گرفتیم، شامل پروداکتهای غیرمجاز، ناموجود، از بین رفته،حذف شده و … هم بود. در واقع با فیکس شدن این مشکل، ما مطمئن شدیم که تمامی پروداکتهای موجود و انتشار یافته در دیجیکالا، در سایت مپ وجود دارند که در بخش ایمپکتها، به این مورد برمیگردم. )

مسیر پروژه و اقدامات انجام شده
مراحل و آمادگی اولیه
در این بخش، به سراغ تک تک کارهای انجام شده، که مهمترین بخش این کیساستادی به حساب میاد، میریم و قدمهای مختلف رو به کمک سورس کد استفاده شده شرح میدیم.
برای حل مشکل سایتمپ به صورت ساختاری، اول از همه باید بتونیم به سوالات زیر پاسخ دقیق بدیم :
- یک : کدام دایرکتوری و صفحات سئو در سایت مپ وجود دارند؟
- دو : ایا تمام urlهای مورد نیاز سئو در سایت مپ وجود دارند؟
- سه : سایت مپ چگونه آپدیت و ساخته میشود؟
برای مورد اول، در وهله اول نیازمند این هستیم که لیستی از تمام url های مورد نیاز سئو، شامل صفحات تگ، فست، صفحات پی ال پی، برند و از همه مهمتر، صفحات پروداکت داشته باشیم.
لیست صفحات همه دایرکتوریهای مطرح شده، به جز صفحات پروداکت، از طریق خروجیای که به کمک تیم پروداکت دیجیکالا گرفته شد و همچنین خروجیهای گرفته شده از api سرچ کنسول، به راحتی بدست اومد. اما همونطور که حدس میزنید، اصلا این بخش از url ها، مسئله ما نبودند، چرا که تعداد کل این صفحات، روی هم رفته به ۵۰۰۰ url هم نمیرسید.
نیازمندی دقیق و سوالی که ذهن ما رو به خودش مشغول کرده بود، فقط یک سوال جدی بود :
“واقعا چه تعداد از صفحات پروداکت دیجی کالا در سایت مپ هستند؟”
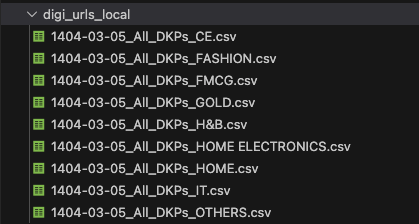
برای پاسخ به این سوال، لیست تمام پروداکتهای موجود در پنل ادمین دیجیکالا، در چندین فایل مختلف خروجی گرفته شد، این فایل شامل تمامی پروداکتهای دیجیکالا به همراه dkp number اونها بود که به صورت ورتیکالی، از هم تفکیک شده بودند :
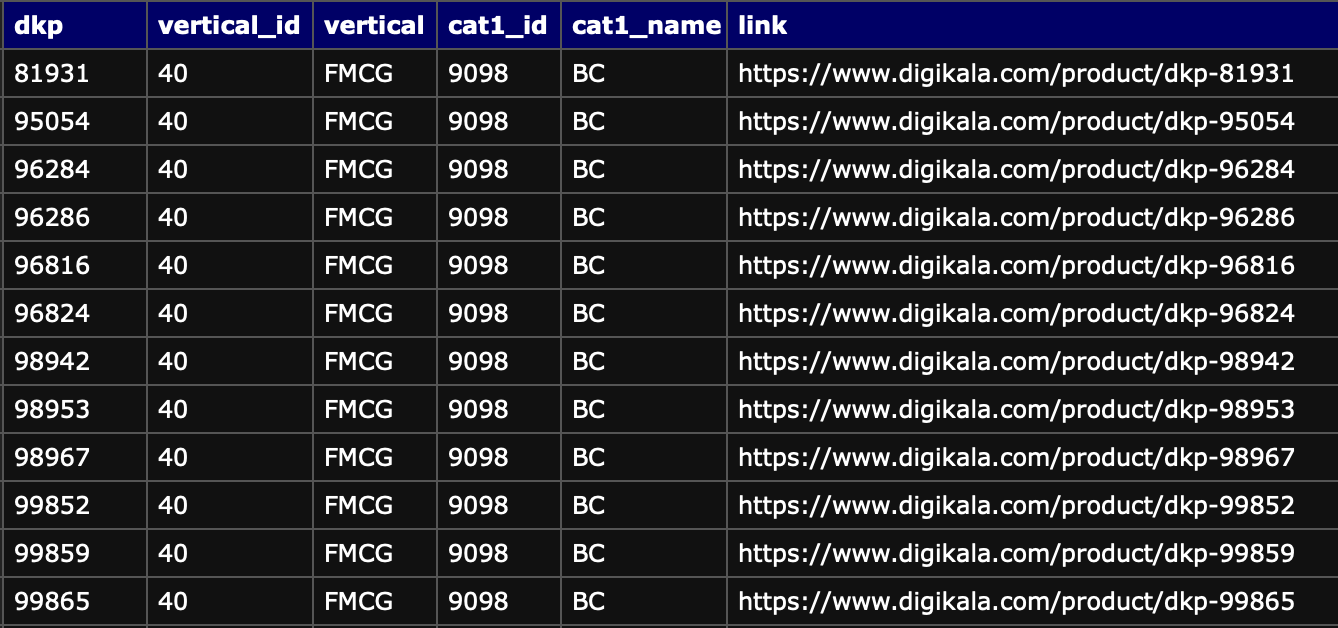
که هر کدوم از این فایل های .csv، چنین اطلاعاتی داخلشون بود :
اولین کاری که باید انجام میشد، مرج شدن تمامی این خروجیها در قالب یک فایل csv بود. به خاطر حجم زیاد row های هر فایل، به سراغ پایتون رفتیم و به کمک لایبرری پانداس، با مرج کردن تمامی این فایل ها، به یک فایل واحد شامل تمامی پروداکتهای لوکال دیجیکالا رسیدیم، فایلی با حجم تقریبی ۲ گیگابایت که شامل ۱۹ میلیون ردیف شامل تمامی پروداکتهای تاریخ دیجیکالا بود :
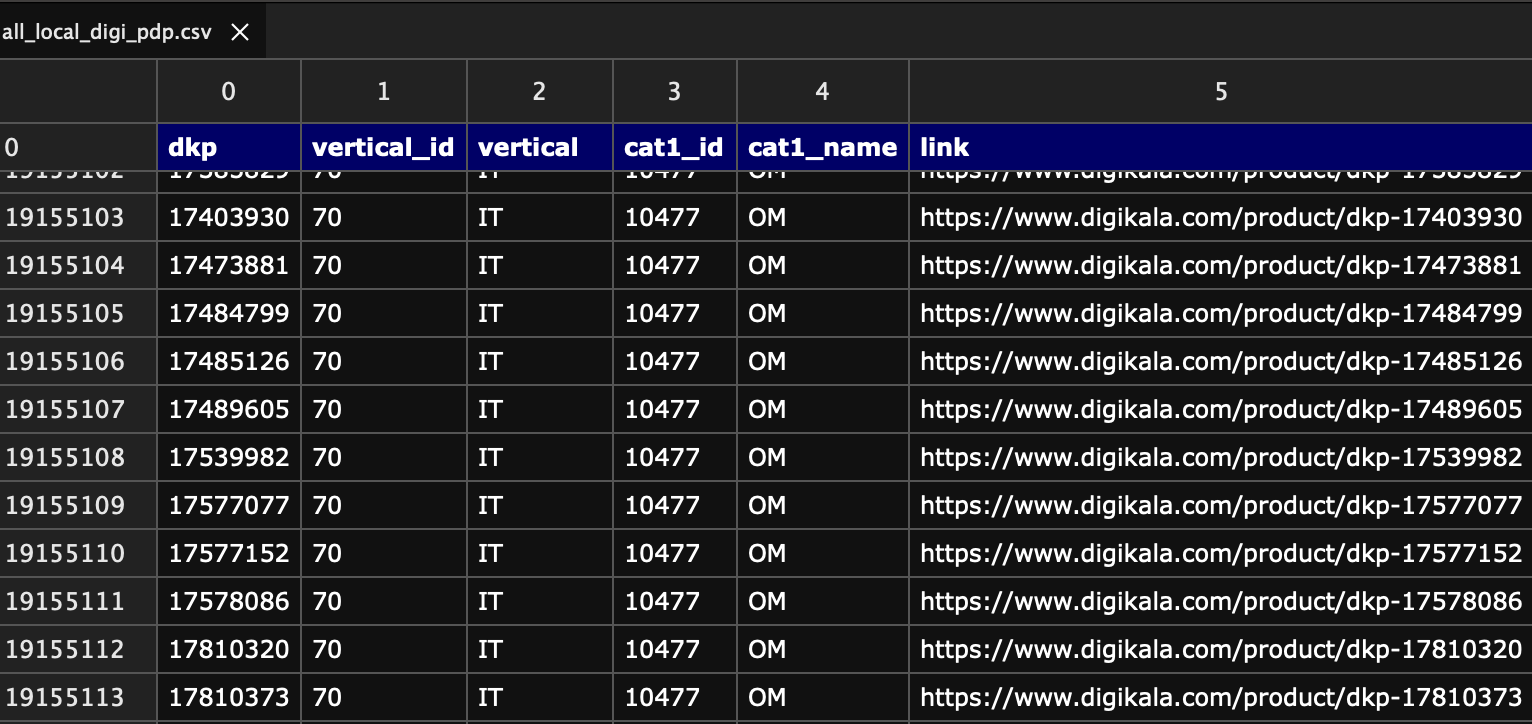
خوب، پس تا اینجا، ما یک فایل داریم که شامل تمامی پروداکتهای لوکال دیجیکالاست. اسم این فایل رو میذاریم :
All_local_digi_pdp.csv
قدم بعدی، مهمترین قدم و اصلیترین کاری هست که در این کیساستادی انجام شد. یعنی آنالیز سایت مپ فعلی دیجی و استخراج تمامی لینکهای پروداکت.
میدونیم که ساختار url صفحات پروداکت دیجیکالا، از چنین ساختاری پیروی میکنه :
پس اگر بتونیم تمامی لینکهای موجود در سایتمپ رو که شامل این path بودند جدا کنیم و داخل یک فایل .csv میریختیم به هدف نزدیک میشدیم.
اما یه چالش مهم اینجا وجود داشت. اولا همونطور که گفته شد، تمامی سایتمپهای دیجی کالا، داخل فایلهای .gz قرار داده شده بودند و برای رسیدن به اونها، اول باید اسکریپتی میداشتیم که بتونه این gzip ها رو اکسترکت کنه. برای انجام این کار، ۲ راه حل کلی دنبال شد.
- یک : ریکوئست مستقیم به سایت مپ دیجیکالا و اکسترکت تک به تک فایلهای gzip
- دو : دانلود تمامی gzip و تقسیم اونها به chunk ( تکه )های کوچکتر برای آنالیز راحت و دقیقتر
در این پروژه، راهحل دوم انتخاب شد، چرا که در راهحل اول، به خاطر حجم زیاد ریکوئست به تک تک فایلهای جیزیپ، توسط سرورهای دیجی امکان ban شدن وجود داشت و عملا تا یک حجمی از ریکوست، میتونست توسط این روش زده بشه.
در ادامه، تک تک اسکریپتهای اصلی و فانکشنهای مختلف این مورد توضیح داده شده اما قبل از بررسی این بخشها، خوبه که تولز و تکنولوژی های مطرح شده رو در همین اول کار بررسی کنیم:
- Jupyter notebook
- Python
- Pandas & gzip & beautifulsoup & Matplotlib libraries
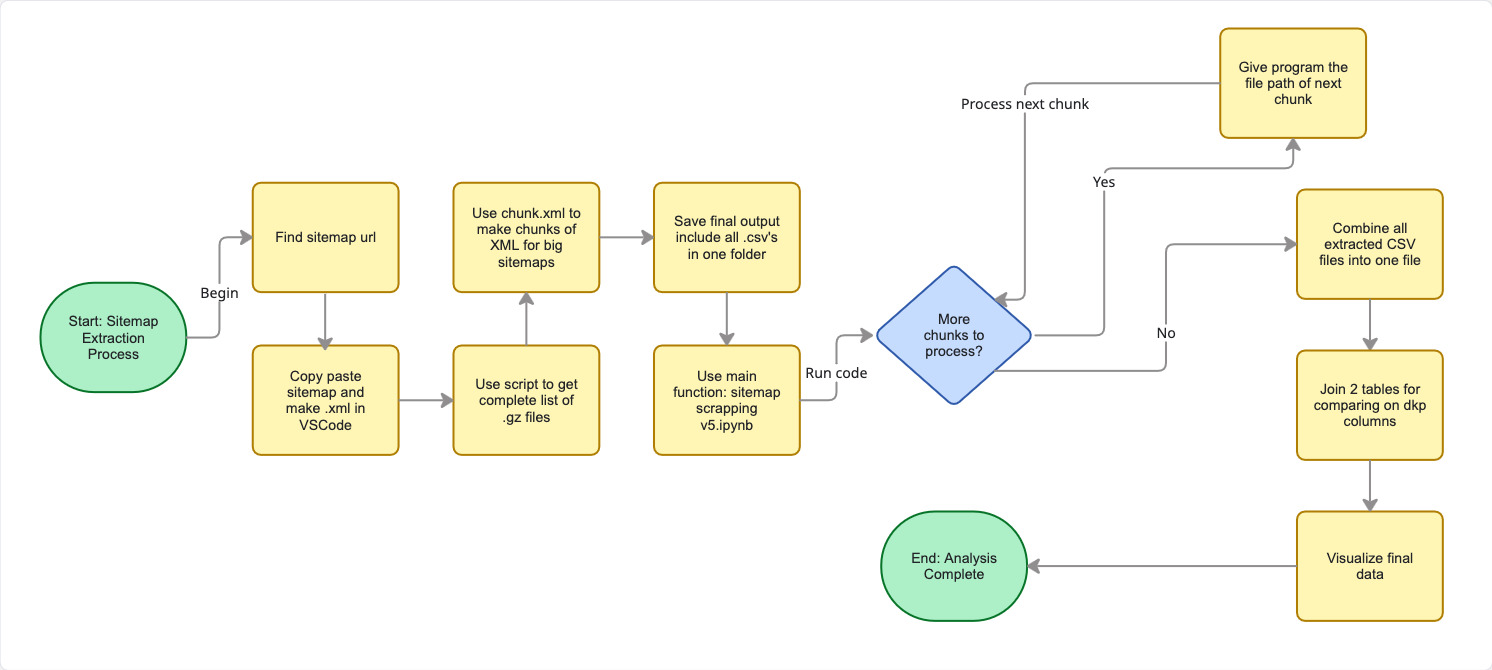
فلوچارت کلی پروژه
به صورت کلی، با یک نگاه، میتونیم به کمک فلوچارت زیر، تمامی مراحل انجام شده در این پروژه رو بررسی کنیم.
حالا که متوجه کلیات این پروژه شدیم، وقت اون رسیده که فانکشنهای مهم رو بررسی کنیم.

“منتظر کامنتهاتون هستم، خوشحال میشم اگر این داکیومنت رو خوندید، حتما نظرتون رو در بخش نظرات با من به اشتراک بذارید.”
فانکشنهای اصلی پروژه
همونطور که گفته شد، هسته اصلی این پروژه، به کمک پایتون و لایبرری پانداس نوشته شد.
# Import necessary libraries
import requests
import gzip
import re
import pandas as pd
from bs4 import BeautifulSoup
from urllib.parse import urljoin
import os
from pathlib import Pathدر قدم اول، کاری که با این اسکریپت انجام میشه، به این شکل بود که از کاربر، نحوه اکسترکت کردن فایلهای gzip پرسیده میشد. اینکه کاربر قصد داره آدرس url سایت مپ رو دستی وارد کنه، یا اینکه از سولوشن بعدی یعنی اپلود فایل لوکال از سیستم خودش، استفاده کنه. ( طبق توضیحاتی که داده شد، ما از سولوشن اول در کد، یعنی استفاده از فایل لوکال استفاده کردیم. )
# Step 1: Prompt user to choose between local file or URL
def get_sitemap_source():
"""Prompt user to choose between a local sitemap file or a URL."""
print("Choose sitemap source:")
print("1. Local file (e.g., '/Users/sitemap scraping/samplesitemap.xml')")
print("2. URL (e.g., 'https://www.digikala.com/sitemap.xml')")
choice = input("Enter 1 or 2: ").strip()
if choice == '1':
file_path = input("Enter the path to the local sitemap file: ").strip()
# Validate file existence
if not Path(file_path).is_file():
print(f"Error: File '{file_path}' does not exist. Please check the path and try again.")
return None, False
print(f"Using local file: {file_path}")
return file_path, False
elif choice == '2':
url = input("Enter the sitemap URL: ").strip()
# Ensure URL has a scheme
if not url.startswith(('http://', 'https://')):
url = 'https://' + url
print(f"Using URL: {url}")
return url, True
else:
print("Invalid choice. Please enter 1 or 2.")
return None, False
در قدم دو و سه و چهار، با توجه به ورودی کاربر در قسمت قبلی، فانکشنهای مرتبط با انتخاب کاربر، فراخوانی میشدند. این فانکشنها مستقیم با اکسترکتکردن فایلهای سایتمپ داخل هر gzip مرتبط هستند.
# Step 2: Function to download and save a .gz file
def download_gz_file(url, save_path):
"""Download a .gz file from a given URL and save it locally."""
try:
response = requests.get(url, stream=True)
response.raise_for_status() # Check for request errors
with open(save_path, 'wb') as f:
f.write(response.content)
print(f"Downloaded: {save_path}")
return True
except requests.RequestException as e:
print(f"Error downloading {url}: {e}")
return False
# Step 3: Function to extract sitemap XML from a .gz file
def extract_sitemap_from_gz(gz_path):
"""Extract XML content from a .gz file."""
try:
with gzip.open(gz_path, 'rt', encoding='utf-8') as f:
return f.read()
except Exception as e:
print(f"Error extracting {gz_path}: {e}")
return Noneبرای مثال در این فانکشن، یعنی parse_sitemap، همونطور که از اسم این مورد پیداست، با استفاده از کتابخانه beautifulsoup، تک به تک سایتمپهایی که داخل gzip یا nested sitemap ها هستند اصطلاحا parse میشدند و دیتای نهایی برگردونده میشد :
# Step 4: Function to parse sitemap and find .gz files or nested sitemaps
def parse_sitemap(sitemap_content, base_url=None):
"""Parse sitemap XML to find .gz files or nested sitemaps."""
gz_files = []
nested_sitemaps = []
try:
soup = BeautifulSoup(sitemap_content, 'xml')
# Find all <loc> tags
for loc in soup.find_all('loc'):
url = loc.text.strip()
# Ensure absolute URL
if base_url and not url.startswith(('http://', 'https://')):
url = urljoin(base_url, url)
if url.endswith('.gz'):
gz_files.append(url)
elif url.endswith('.xml'):
nested_sitemaps.append(url)
return gz_files, nested_sitemaps
except Exception as e:
print(f"Error parsing sitemap: {e}")
return [], []در قدم بعدی یعنی step5، تمامی لینکهای سایتمپ، که شامل رجکس نوشته شده یعنی دارای /product هستند ، داخل لیست product links ذخیره میشوند.
دلیل فورس کردن این مورد و استفاده از رجکس این بود که ما تنها به دنبال پیدا کردن لیست url های هر پروداکت هستیم، و از اونجایی که در داخل سایتمپهای دیجیکالا، لینک هایی از تصاویر هر پروداکت هم وجود دارند، به خاطر افزایش سرعت و همچنین تمیزتر شدن خروجی نهایی، نوشتن رجکس ضروری و غیرقابل اجتناب بود.
# Step 5: Function to extract product links from sitemap XML
def extract_product_links(sitemap_content):
"""Extract links matching 'www.digikala.com/product/dkp-*' from sitemap."""
product_links = []
try:
soup = BeautifulSoup(sitemap_content, 'xml')
# Find all <loc> tags
for loc in soup.find_all('loc'):
url = loc.text.strip()
# Check if URL matches the pattern
if re.match(r'.*www\.digikala\.com/product/dkp-\d+.*', url):
product_links.append(url)
return product_links
except Exception as e:
print(f"Error extracting product links: {e}")
return []
در نهایت در main function ، اسکریپت نوشته شده با توجه به url یا لوکال فایلی که کاربر وارد برنامه میکنه، سایت مپ رو پردازش میکنه تا همه لینکهای محصولات رو استخراج کنه.
# Step 6: Main function to process the sitemap and extract links
def process_sitemap(sitemap_source, is_url=True):
"""Main function to process sitemap, download .gz files, and extract links."""
all_product_links = []
# Step 6.1: Fetch sitemap content (from URL or file)
if is_url:
try:
response = requests.get(sitemap_source, headers={'User-Agent': 'Mozilla/5.0'})
response.raise_for_status()
sitemap_content = response.text
except requests.RequestException as e:
print(f"Error fetching sitemap {sitemap_source}: {e}")
return []
else:
try:
with open(sitemap_source, 'r', encoding='utf-8') as f:
sitemap_content = f.read()
except Exception as e:
print(f"Error reading sitemap file {sitemap_source}: {e}")
return []
# Step 6.2: Parse initial sitemap to find .gz files and nested sitemaps
gz_files, nested_sitemaps = parse_sitemap(sitemap_content, base_url=sitemap_source if is_url else None)
# Step 6.3: Process nested sitemaps recursively
for nested_sitemap_url in nested_sitemaps:
print(f"Processing nested sitemap: {nested_sitemap_url}")
nested_product_links = process_sitemap(nested_sitemap_url, is_url=True)
all_product_links.extend(nested_product_links)
# Step 6.4: Download and process each .gz file
for gz_url in gz_files:
# Create a filename for the .gz file
gz_filename = os.path.basename(gz_url)
save_path = f"./{gz_filename}"
# Download the .gz file
if download_gz_file(gz_url, save_path):
# Extract sitemap from .gz
sitemap_content = extract_sitemap_from_gz(save_path)
if sitemap_content:
# Extract product links
product_links = extract_product_links(sitemap_content)
all_product_links.extend(product_links)
print(f"Extracted {len(product_links)} product links from {gz_filename}")
# Clean up: Remove downloaded .gz file
try:
os.remove(save_path)
print(f"Deleted: {save_path}")
except Exception as e:
print(f"Error deleting {save_path}: {e}")
return all_product_links
و در نهایت، لینکهای استخراج شده در قدم قبلی، در داخل فایل .csv ذخیره میشدند. توجه داشته باشید که هر کدام از این فایلهای csv، تنها بخشی از سایت مپ هستند و در ادامه و در فانکشنهای آنالیز نهایی دیتا که در ادامه توضیح داده شدهاند، باید همه این موارد داخل یک big csv مرج میشدند.
# Step 7: Save links to CSV
def save_to_csv(links, output_file='final_pdp_links_part1.csv'):
"""Save extracted links to a CSV file."""
try:
df = pd.DataFrame(links, columns=['Product_URL'])
df.to_csv(output_file, index=False, encoding='utf-8')
print(f"Saved {len(links)} links to {output_file}")
except Exception as e:
print(f"Error saving to CSV: {e}")فانکشن chunk xml
یک نکته خیلی مهم در این پروژه، کاری بود که در تکه تکه کردن و اصطلاحا ایجاد chunk های مختلف سایت مپ انجام شد. با توجه به اینکه حجم هر کدوم از فایلهای gzip خیلی سنگین بود، نیاز داشتیم تا به صورت مرحله به مرحله، هرکدوم از این فایلهای جیزیپ وارد برنامه بشن. ( یادتون هست که گفته شد ما از راه حل ایمپورت سایت مپ از طریق فایل لوکال استفاده کردیم. )
برای طولانی نشدن متن، از این بخش سریعتر عبور میکنیم. در نهایت، تمامی کاری که در این اسکریپت انجام شد این بود که همونطور که گفته شد، در نهایت به لیست .xml های کوچکتر که هر کدوم از اونها شامل کلی فایل gzip بودند رسیدیم.
که یک نمونه از این سایتمپ ها رو در ادامه میتونید مشاهده کنید:
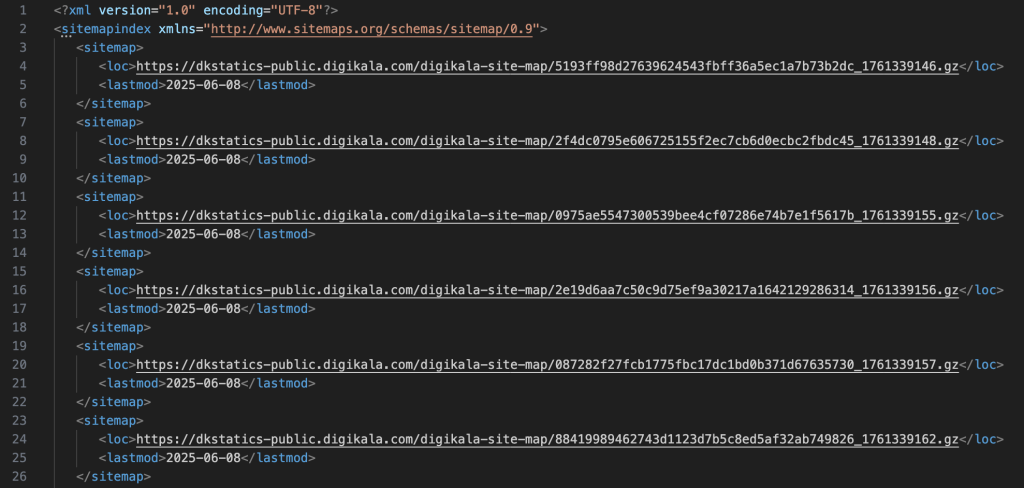
توجه داشته باشید که برای main function که در بالاتر اشاره کردم، در صورتی که قصد از سولوشن ایمپورت دستی سایت مپ از لوکال فایلها از طریق سیستم خودتون رو داشته باشید، اول از همه باید به چنین لیستی برسید و بعد به سراغ main function برید.
فانکشنهای آنالیز دیتا
تا اینجا، تمام کارهایی که تا الان انجام شدند رو،خیلی سریع مرور میکنیم.
۱ – یکی کردن تمامی فایلهای .csv شامل اطلاعات پروداکتهای دیجیکالا که اسم این مورد به شکل زیر نوشته شد:
All_local_digi_pdp.csv
۲ – استفاده از فانکشن chunk xml برای تکه تکه کردن حجم بزرگ سایت مپ به xml های کوچکتر برای استفاده در فانکشن اصلی
۳ – کار روی چگونگی اکسترکت کردن لینکهای هر سایت مپ شامل مسیر /product در main function
۴ – خروجی گرفتن از قدم قبلی به ازای هر کدام از چانکهای سایت مپ در قدم دوم و رسیدن به فایل نهایی پروداکتهای استخراج شده از تمامی سایت مپ ها که اسم این مورد هم به صورت زیر گذاشته شد:
all_sitemap_extracted_pdp.csv
حالا میرسیم به بخش هیجان انگیز ماجرا و آنالیز دیتا.
کاری که ما اینجا میخوایم بکنیم اینه که حالا باید به کمک توابع مختلف پانداس و کمی دانش sql، به کمک پانداس، ۲ فایل نهایی که یکیشون شامل تمامی پروداکتهای لوکال دیجی کالا و اون یکی شامل تمامی پروداکت های استخراج شده هستند رو با همدیگه مقایسه کنیم.
در بخش اول، تمامی csvهای شامل پروداکتهای لوکال دیجی کالا ( همونایی که تو قسمت قبلی خروجی گرفتیم ) merge شدند.
import pandas as pd
import glob
import os
# Path to the folder containing CSV files
csv_folder = '/Users/mahdi/Desktop/source code/backuped online/sitemap/main files/digi_urls_local'
# Get all CSV file paths
csv_files = glob.glob(os.path.join(csv_folder, '*.csv'))
# Merge all CSVs
merged_df = pd.concat((pd.read_csv(f) for f in csv_files), ignore_index=True)
# Save the merged dataframe
merged_df.to_csv('all_local_digi_pdp.csv', index=False)
برای اینکه مطمئن باشیم که این پروسه یکی شدن به درستی انجام شده، len این csv نهایی اندازه گیری میشه تا تعداد پروداکتهای مرج شده رو متوجه بشیم :

فایل نهایی این بخش به این صورته که شامل همون ۱۹ میلیون پروداکت کلی هست که ما دیتاش رو از دیتای خود دیجیکالا گرفتیم.
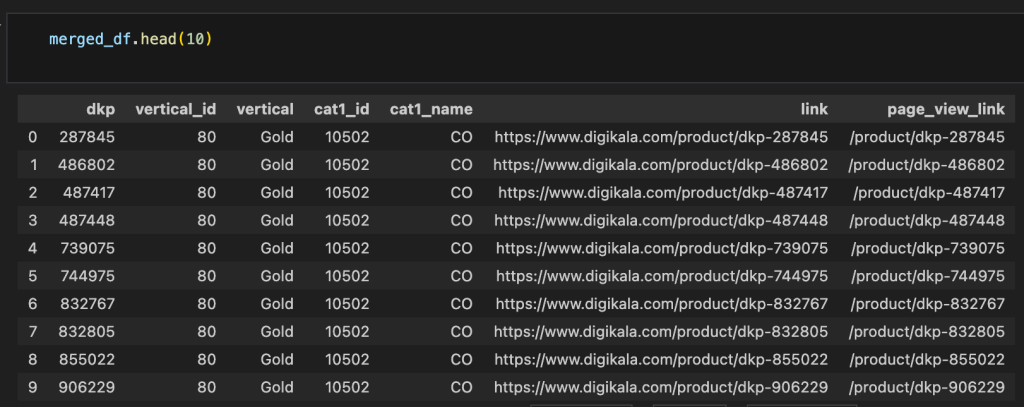
حالا سراغ csv نهایی خروجی گرفته شده از main function که شامل تمامی پروداکتهای استخراج شده از سایت مپ هستند میریم. برای اینکه بتونیم ارتباطی بین این تیبل و تیبل قبلی در تصویر بالا برقرار کنیم، باید یک ستون مشترک در جفت این تیبل ها پیدا میشد. همونطور که میدونید ساختار صفحات پروداکت دیجی کالا به این صورته:
پس اگر dkp number هر پروداکت که یک عدد یونیک به ازای هر پروداکت هست پیدا بشه، میتونیم در قدم بعدی این ۲ تیبل رو با همدیگه جوین بزنیم. به خاطر همین از این اسکریپت برای اکسترکت کردن این dkp number در فایل دوم استفاده شد :
import re
# Load your CSV
df = pd.read_csv(all_sitemap_extracted_pdp.csv')
# Define a function to extract the 'dkp-*' pattern from a row (as a string)
def extract_dkp_id(row):
match = re.search(r'dkp-\w+', str(row))
return match.group(0) if match else None
# Apply to each row (row-wise search across all columns)
df['dkp_id'] = df.apply(lambda row: extract_dkp_id(' '.join(row.values.astype(str))), axis=1)
# Save the updated file
df.to_csv('all_sitemap_extracted_pdp.csv', index=False)
#just extract the id from dkp-id
df['dkp_numeric'] = df['dkp_id'].str.extract(r'dkp-(\d+)')
در نهایت به چنین خروجیای میرسیم :
فقط یه قدم تا رسیدن به دیتای نهایی وجود داره. سوال مهمی که در ذهن داریم رو یادتونه؟ :
چه تعداد از صفحات پی دی پی ما، در سایت مپ وجود دارند؟
در اسکریپت بعدی، با join زدن دو csv نهایی با کلید dkp numeric از تیبل دوم با ستون dkp از تیبل اول، به جواب این سوال میرسیم :
# Load the two CSVs
file_a = pd.read_csv('/final analysis/all_local_digi_pdp.csv') # The main dataset contains all digi urls - local export
file_b = pd.read_csv('/final analysis/all_sitemap_extracted_pdp.csv') # The sitemap dataset contains the urls in sitemap with new dkp extracted column - actual sitemap export
# Convert IDs to string (for consistent comparison)
file_a['dkp'] = file_a['dkp'].astype(str)
file_b['dkp_numeric'] = file_b['dkp_numeric'].astype(str)
# Create a set of sitemap IDs for fast lookup
sitemap_ids = set(file_b['dkp_numeric'])
# Create a new column based on existence in sitemap in main dataset file ( digi all urls )
file_a['in_sitemap'] = file_a['dkp'].apply(lambda x: 'yes' if x in sitemap_ids else 'no')
# Save the result
file_a.to_csv('final_sitemap_analysis_26oct.csv', index=False)
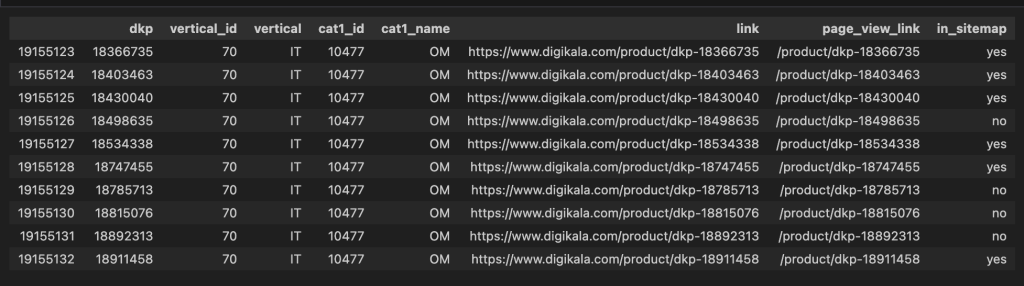
و ریزالت نهایی اینجاست! اونجایی که با ذوق و اشتیاق، میتونیم حاصل تمامی صحبت ها و کارهایی که تالان کردیم رو، در ستون in_sitemap ببینیم. این ستون به سوال مهمی که به دنبالش بودیم پاسخ میده :

ویژوالیزیشن و خروجی نهایی
کار اصلی در اینجا تموم میشه، اما حالا باید سراغ ویژوالیزیشن دیتا بریم تا بتونیم کارهای انجام شده رو، به زبان خیلی ساده تر، به ذینفعان شامل تیم فنی، پروداکت و تیم سئو گزارش بدیم.
برای مثال، سوال اول در اینجا این بود که چه تعداد از پروداکتهای هر ورتیکال، در سایت مپ وجود داشتند؟
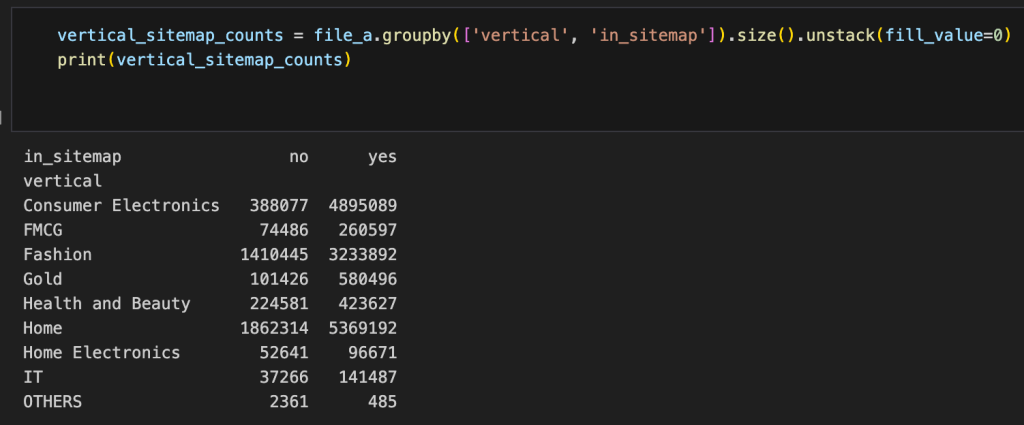
و در ادامه، همین دیتا با استفاده از لایبرری Matplotlib، به شکل بهتری نمایش داده شد :
import matplotlib.pyplot as plt
# Prepare the grouped data
vertical_sitemap_counts = file_a.groupby(['vertical', 'in_sitemap']).size().unstack(fill_value=0)
# Plot
vertical_sitemap_counts.plot(kind='bar', stacked=True, figsize=(10, 6))
plt.title('In-Sitemap Status by Vertical')
plt.xlabel('Vertical')
plt.ylabel('Number of Products')
plt.legend(title='In Sitemap')
plt.tight_layout()
plt.show()
“منتظر کامنتهاتون هستم، خوشحال میشم اگر این داکیومنت رو خوندید، حتما نظرتون رو در بخش نظرات با من به اشتراک بذارید.”
جمعبندی پروژه – نکات نهایی
پروژههای بزرگ، با توجه به تاثیرات عمده ای که بر روی حجم بزرگی از url ها و صفحات سایت میذارن، از اهمیت بالایی برخوردار هستند. اپتیمایزیشن سایت مپ هم با توجه به تاثیرات مستقیم و بالکی که بر روی حجم بزرگی از صفحات ما گذاشت، اهمیت این بخش رو مجدد بهمون یادآوری کرد.
انجام تسکهای بزرگ در سازمانهای بزرگ، با توجه به وجود تیمهای گوناگون، نیازمند پیروی از تک تک مراحل زیر است:
- بررسی کامل چیستی و اثر احتملای پروژه
- ایجاد داکیومنت پروژه
- هماهنگی با تیمهای پروداکت و فنی و …
- آنالیز و کنترل کیفیت پروژه
- و در نهایت بررسی ایمپکت پروژه انجام شده و گزارش به تیمهای مرتبط
عدم انجام درست هر کدام از مراحل بالا، نه تنها پیشبرد پروژه رو به تعویق میندازه، بلکه در ایجاد فهم مشترک بین تمامی نفرات و تیمهای مختلف اثر منفی میذاره.
تاثیرات عمده این پروژه و پروژههای این چنینی، نشون میده که سئو و مخصوصا تکنیکال سئو، دیگه مانند گذشته، صرفا از حالت انجام چند تسک معمول چک لیستی خارج شده و باتوجه به تاثیرگذاریهای مهمی که این فانکشن میتونه در بهبود متریکهای مختلف مارکتینگ + بیزینس بذاره، بیش از قبل نیازمند توجه و اعتماد سایر سکشنها شامل تیم پروداکت، فنی و مارکتینگه.
درس مهم دیگری که از این پروژه گرفتیم، این بود که فایل سایت مپ، تنها یک فایل ساده و بی اثر نیست، بلکه در سایتهای بزرگ، به علت تاثیر مهمی که در نحوه کراول شدن بهتر حجم بزرگی از صفحات، ایندکسینگ بهتر و … بذاره، بیش از پیش نیازمند توجه، بهبود و مانیتورینگ منظم و همیشگیه.
پینوشتهای قلبی
یک : این پروژه بدون حمایتها و زحمات اصلی که بر گردن رضا شاهنظر عزیز بود، نمیتونست به عنوان یک پروژه تاثیرگذار، در تاریخ دیجیکالا ماندگار بشه.
دو : از لیام لسانی عزیز، بابت تک به تک کامنتهایی که برای بهبود این داکیومنت گذاشت ممنونم. بدون ویراستاریهای لیام، این داکیومنت هیچوقت تکمیل نمیشد.
سه : تدوین این داکیومنت، ساعتهای بسیار زیادی ازم وقت گرفت، هدف اول من همواره داکیومنت کردن پروژهها برای اندازهگیری و اهمیت پروژههای انجام شده است. اما در زمان تدوین این داکیومنت، همواره در ذهنم، به بعد آموزشی این مورد هم فکر میکردم و امیدوارم برای هرکدام از بچههای اکوسیستم سئو و اکوسیستم تک ایران که این داکیومنت رو مطالعه میکنند، مطالب اشاره شده در این داکیومنت مفید واقع بشه.
چهار : بابت صفر تا صد پیگیری این پروژه، تک به تک جلسات رفته شده و موارد مختلفی که در طی این مسیر یاد گرفتم و اثرات بزرگی که برای دیجیکالای بزرگ ساختیم، بسیار خوشحالم.
پنج : تاریخ تدوین این داکیومنت در آذرماه ۱۴۰۴ بود. به علت اتفاقات پیشآمده و غمهای متداول و همیشگیای که در ایران دچارش هستیم، انتشار این مطلب به تعویق افتاد.
شش : منتظر کامنتهاتون هستم، خوشحال میشم اگر این داکیومنت رو خوندید، حتما نظرتون رو در بخش نظرات با من به اشتراک بذارید. امیدوارم در آینده هم فرصت کافی برای ساخت چنین کیساستادیهایی رو داشته باشم.
لینکهای مفید :
22 پاسخ
چه مطالب مفید و کاربردی 👏🏽
کمتر کسی مثل شما پیدا میشه که انقدر در اموزش و یاد دادن بخشنده باشه.
واقعا ممنونم
سلام. ممنونم نظر لطفتونه. نه واقعیتش آدمهای دیگر و کاربلدتری هم هستند. من فقط تو این مورد تلاش میکنم همین 🙂 لطف دارید و مرسی بابت پیامتون.
کامل ترین و جامع ترین بهینهسازی سایتمپ بود که تا به امروز دیده بودم.
پوشش این حجم کوئری محصول کاری بسیار زمان بر و منحصر به فرد بوده که شما از پسش بر اومدید. زنده باد !
لطف دارید. ممنوم از کامنتتون. خوشحالم که اینطوری بوده
بسیار عالی
ممنون محمدجان تشکر.
خسته نباشی مهدی جان،
واقعا کار بالک و خفنی بود.
کارت درسته
امیرجان همیشه لطف داری به من. دمت گرم بابت کامنتت ❤️
مهدی جان منی که هر روز تلاش هات رو میدیدم، متوجهم که این پروژه از دور ساده ولی از نزدیک به شدت پیچیده، فرسایشی و عجیب و غریبه و چقدر با دقت این کار رو انجام دادی و نتیجش رو همگی مون با پوست و گوشت درک کردیم.
ممنونم بابت تمام زحماتت و همچنین اشتراک دانشت❤️
سروش جان مثل همیشه بابت همراهی ها و هم صحبتی هایی که باهم داریم ازت ممنونم. نظر لطفته و قطعا مواردی که گفتی متقابله. دمت گرم سلطان ❤️
مطالعه این کیساستادی نشان میدهد که در وبسایتهای بزرگ، مشکلات ایندکسینگ همیشه ناشی از محتوا یا لینکسازی نیستند و گاهی بهینهسازی ساختارهای فنی مانند Sitemap میتواند تأثیر قابلتوجهی بر نحوه Crawl و Index صفحات داشته باشد. نکته جالب برای من، رویکرد دادهمحور در تحلیل وضعیت قبل و بعد از اعمال تغییرات بود. انتشار چنین تجربیات واقعی از پروژههای بزرگ ایرانی برای جامعه سئو بسیار ارزشمند است. سپاس از اشتراکگذاری این تجربه.
یاشارجان تشکر از اینکه وقت گذاشتی و مطالعه کردی و کامنت گذاشتی، خوشحالم که مفید بوده دم شما گرم.
کیساستادیهای واقعی مثل این، از دهها مقاله آموزشی کاربردیتر هستند. سپاس از اشتراکگذاری تجربه.
سعید عزیز تشکر بابت پیامت. خوشحالم که مفید بوده.
case study بسیار جالبی بود ممنون که به اشتراک گذاشتیش
سلام علی عزیز. ممنون ازت که بررسی کردی و کامنت گذاشتی دم شما گرم.
بسیار کاربردی و مفید
همیشه بدرخشی👏🏻❤️
ارادت. ❤️
مثل همیشه عالی👏🏻
ممنونم یگانه جان. تشکر ❤️
سلام
خداقوت.چقدر جای این نوع case study ها در کامیونیتی سئو ما خالیه.به سهم خودم ممنونم که مستند و منتشر کردید.
موفق باشید.
درود سیناجان. ممنونم از نظرت دم شما گرم.